

Text
https://drive.google.com/drive/folders/1VDogTkf6hmtu_0EfC7UHBXl2T73eHTa9?usp=sharing
Compositing Images
https://drive.google.com/drive/folders/16WvPthwTIkz_lxsgyri9h51a2U0JBMkV?usp=drive_link
Reference Images
https://drive.google.com/drive/folders/12L1qD-I-bcZmjm8BsNndewY1qUhRzoxx?usp=sharing
Crackle Masks
https://drive.google.com/drive/folders/15NvKcMnvLKpOof26ztbSY-Hmtwag14y2?usp=sharing
I present 4 passages from the following main segments:
- 20231005123336 (first letters area)
- 20230702185753
- 20231012184423
- 20231106155351 + 20231022170901
Each one also has overlapping segments that are layered on top with various blend modes. The composite image is the one I used for character/word detection. Each composite is made from direct outputs generated programmatically from a modified version of the open sourced firs ink/letter code. I used the segmentation team’s released tif stacks which used the CT data inputs. No manual annotations of character or text were made. All manipulations were made with various blend modes between direct outputs. Mostly multiply, darken, screen, and soft output were used. More details in discussion.
I’ve also included letters/words detected from additional segments. These appear to have less ink density and to my eye, less legible continuous plausible text. I’ve ordered them from highest confidence to lowest- thus the first 4 are the ones I believe have the highest accuracy but I’ll leave judgment to the papyrologists/review board.
I’m still working on stuff so may resubmit if I achieve better results. At the very least, I expect to consolidate and send over additional supporting materials over the next few days.
I’ve put together a list of links to relevant materials below.
Let me know if you have any issues accessing or opening any of them.
LINKS
–Submission PDF: SUBMISSION_v2.pdf
-Submission DOC: Submission_v2.doc
https://docs.google.com/document/d/13pQKFqdL3WWA_4W8lp2wb3CCJxDTqTyGvXJsF7Nvg0g/edit?usp=sharing
-Github repo: inkception-3d
https://github.com/lucyellu/inkception-3d
-inference_notebook.ipynb
https://drive.google.com/file/d/1kxj5RU0BrZ1svhtvf2NqlwgLYy_TLpDQ/view?usp=drive_link
-inference_stride32.py
https://drive.google.com/file/d/1YHe3BUdu2DgyvZ9m0sncguNKNrZSjg2d/view?usp=drive_link
-letter_grid.ipynb
https://drive.google.com/file/d/1j7a8eN37JYm_RUcBrwgPZUqNfGX55ZY0/view?usp=drive_link
-Google drive downloads:
-Data
-Scanned images
https://drive.google.com/drive/folders/1fBeRPUH9SE1OzCITMlNZkN3YeNRqNYOt?usp=drive_link
https://drive.google.com/drive/folders/14ejfQ5szzY2sjdXlk74RD4E3eZOp7MWS?usp=drive_link
-NOink
https://drive.google.com/drive/folders/1ADkFHVwC2wANggqMGLqQ81jqCEGtqsCm?usp=drive_link
-Paper
https://drive.google.com/drive/folders/19rH44JwR-PL_auYJbIukXjUellVrCRwB?usp=drive_link
-Greek OCR
https://drive.google.com/drive/folders/1WhBFwV_KCwNVtWDM_RLFhLvuVmLzewQd?usp=drive_link
-Finetuning masks: Training_segments.zip
-Youseff’s checkpoint
https://drive.google.com/file/d/1SAcCUi7tdAnI8tfuygh2s2u3hvfdZan6/view?usp=drive_link
-3D Files
-Blender
https://drive.google.com/drive/folders/14ct5MFSMTutGlv3o7xIlWoPro3LDLgLA?usp=sharing
-Maya
https://drive.google.com/drive/folders/1riLSxISfxWfToJFwAuNLhkIMGDdnnoLQ?usp=sharing
-FBX
CONTENTS
- Passages
- Detected text
- Possible characters/letters
- Possible words/passages
- Segments
- Segmentation output: tif layers, average surface tif, obj mesh
- Public model’s output
- Composited Output
- Characters
- Compositing
- Overlapping separate segments
- Overlapping pages within segments
- Data
- Depth separations (pages/wraps)
- Landmarks
- Crackle
- Machine Learning
- Architecture
- Inference
- Training/Finetuning
- Replication
- Github repo
- Segment outputs (.zip)
- 3D scenes/mesh (fbx)
- Supplementary photos/videos
- 3D Unwrapping, Spatial Segmentation
- Non-linear deformers
- Manual vertex manipulation
- Spiral generation
- Damage simulation
- 3D slicer revealing of segments
- 3D Ink Detection
- Manual replication of kaggle model
- 65 tif stack image arrays
- Subsurface scattering
- Volume shaders
- Mesh to volume
- References/Downloads
- CT Scans: 14k Slices (masked volume, axial crackle: khartes_chuck)
- Segmentation/Segments: 65 Slices (maya, blender, after effects
- SAD Scans: Blank Papyrus, Ink/NoInk, Replica fragments/scroll
- Airfryer Carbonized Scans
I present passages from the following segments *
-Segment 3: 20231012184423 (2 passages)
-Segment 4: 20231106155351 + 20231022170901 (20231022170900_superseded)
-Segment 5: 20231106155351
-Segment 6: 20231210121321 +
-Segment 7: 20231031143852 + 20231022170901 (20231022170900_superseded)







oduction
Vesuvius was more than a machine learning problem to me- presenting challenges across diverse domains ranging from topology to Ancient Greek translations.
My approach felt more akin to fossil excavation, where I was chipping or brushing away debris to reveal the underlying object- more so than putting things together.
Like digging up dinosaur bones. Gather as much signal as possible, then go in manually to remove noise. Adjusting the model to pick up more signal felt like excavating a whole square meter of dirt. Compositing then felt like blowing or brushing away the clutter.
This scroll is basically a cylindrical stone tablet. It’s been fossilized from paper to rock.
3D
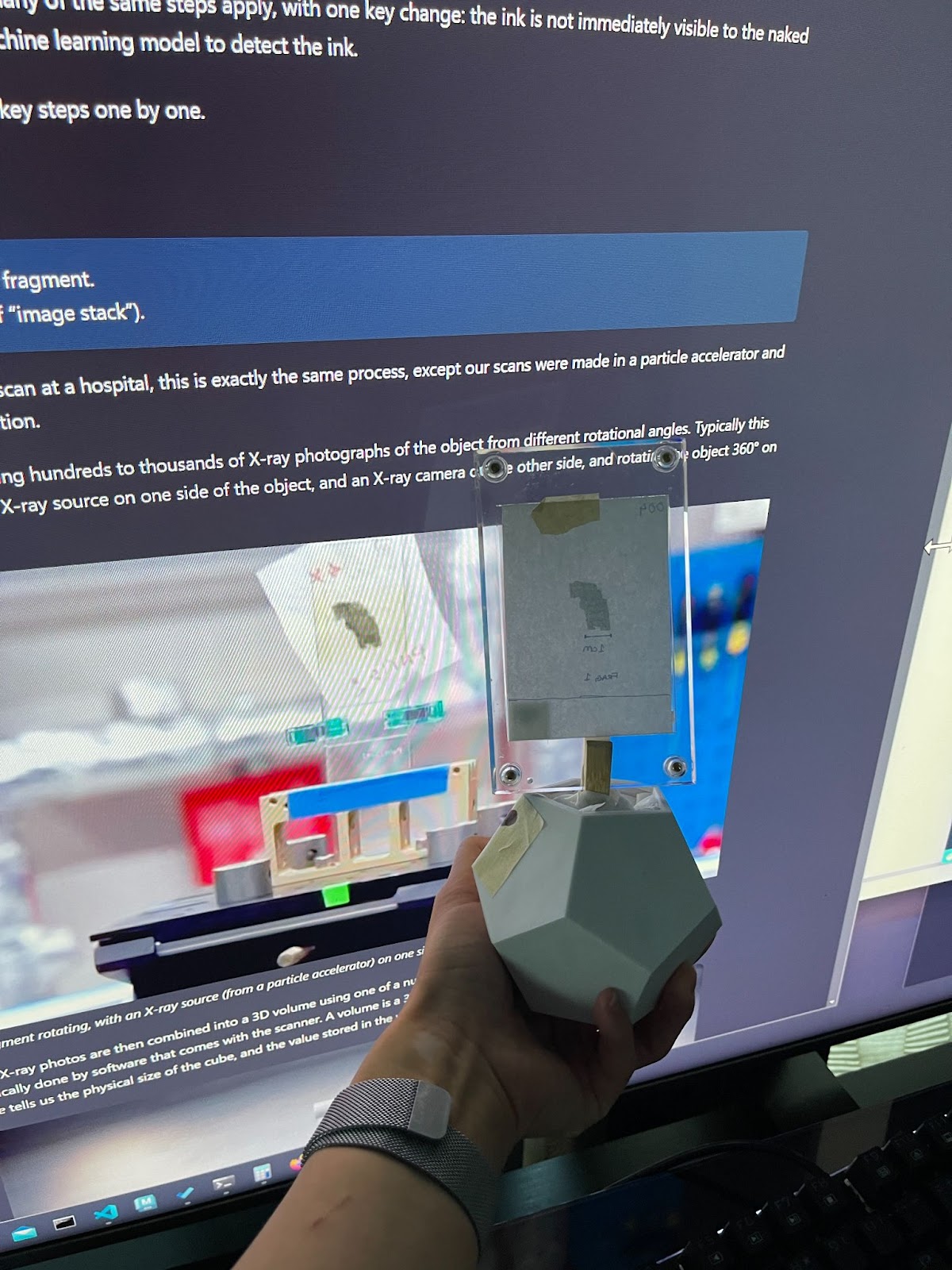
Someone mentioned that at the heart of it this is a geometry problem. I instantly agreed, as intuitively I just wanted to get a good grasp of what we were dealing with on a physical/spatial level.
How big is this thing? How does it look from every angle? I wanted to hold it up to the light and examine it from different views. So one of the first things I set about was to create a digital clone that I could play with in 3D space.
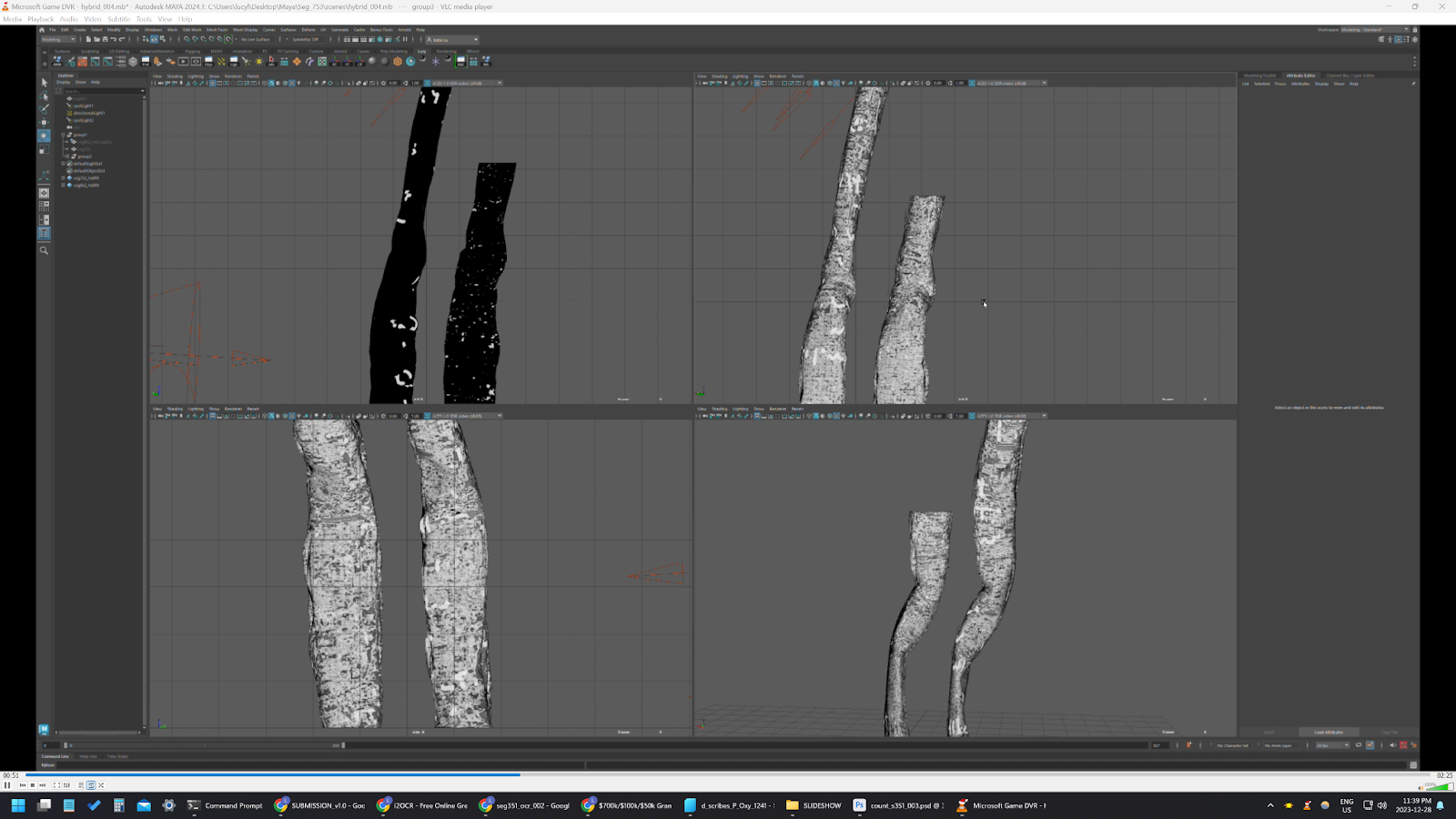
This involved bringing in the obj meshes of each segment, downsampling it to 1% poly count, and then referencing them into a new scene. I only managed to get up to 10 or so segments to work within one scene. But it was still immensely helpful to see how the pieces link up to one another.
There are definitely places where the segments overlap, with the geo straight up crashing.
The vast majority of my work was with Scroll 1. I did do some initial tests with Scroll 1667. I’ve included hand drawn masks of crackle from scroll 4:
340: Layer 57 (mentioned by Luke)
640: Layer 60 (alpha mentioned by Rapushko)
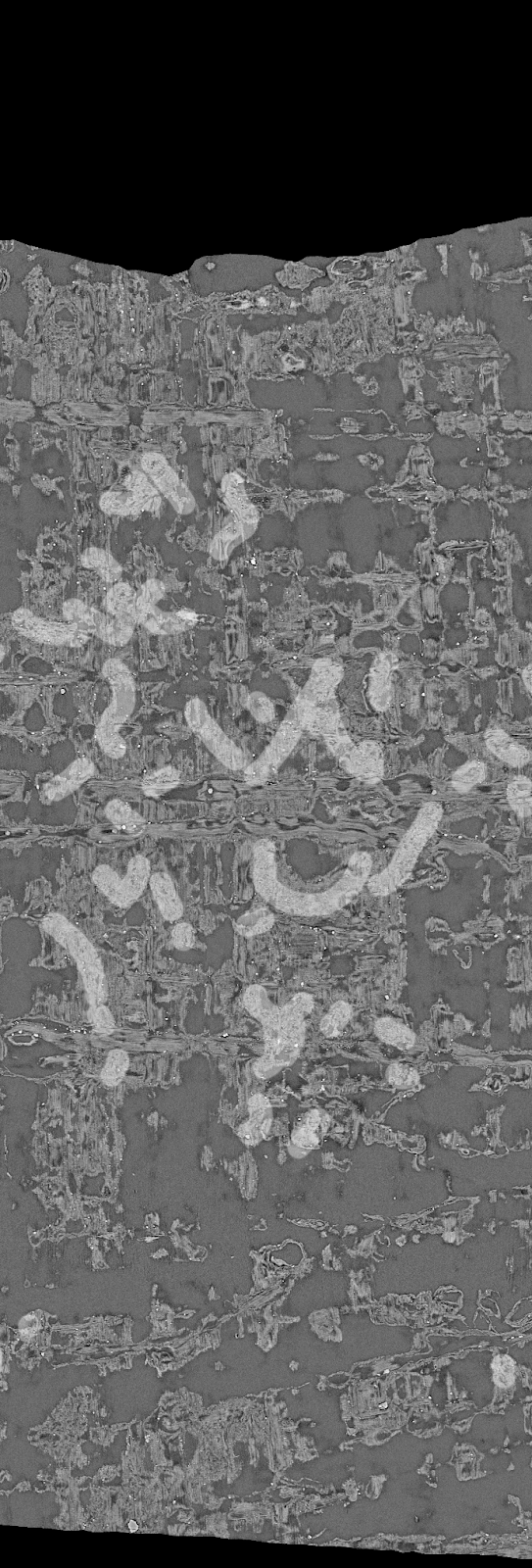
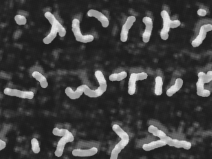
My theory is that the crackles are microtears from the ink as you can see the direction of brush/pen strokes. I bought some reed pens and carbon ink to try writing on papyrus myself, and found myself repeating certain strokes to get certain characters.
This became especially apparent with longer passages when I found myself seeking shortcuts. The alpha symbol for example tends to follow the star shape.
You can distinguish certain shapes by follow the trails of the crackle. Similar to the trails left behind by old school plane sky writers.
There’s a certain orientation to the pattern, and it’s stenciled rotation is a tell-tale sign of ink crackle as opposed to the larger crackle pattern.
The larger pattern may be larger sheets fracturing. I think the ink may have fused with the paper and then cracked under distress. In any case, the scale of the textures are extremely relevant.
I tried segmenting with the various tools but didn’t manage to get anything useful. Volume cartographer took forever to spin up and then the software itself was so laggy (perhaps due to xview)
Khartes was better, but I didn’t manage to get vc render to work quite right.
I decided I may be better off separating out the overlapping segments as I knew segment 852 overlapped with 753. Seg 753 was curiously one of the only ones that had the normals facing outwards. Most were facing inwards, which makes sense as the ink should be on the inside of the scroll.
I found that using the reverse output as a subtractive mask was helpful in eliminating noise
Youseff-output:

Youseff-output-reversed:

Composite mask:

Notice the artifacts that seems to be from paper bending are materially diminished as they cancel each other out.
Passages
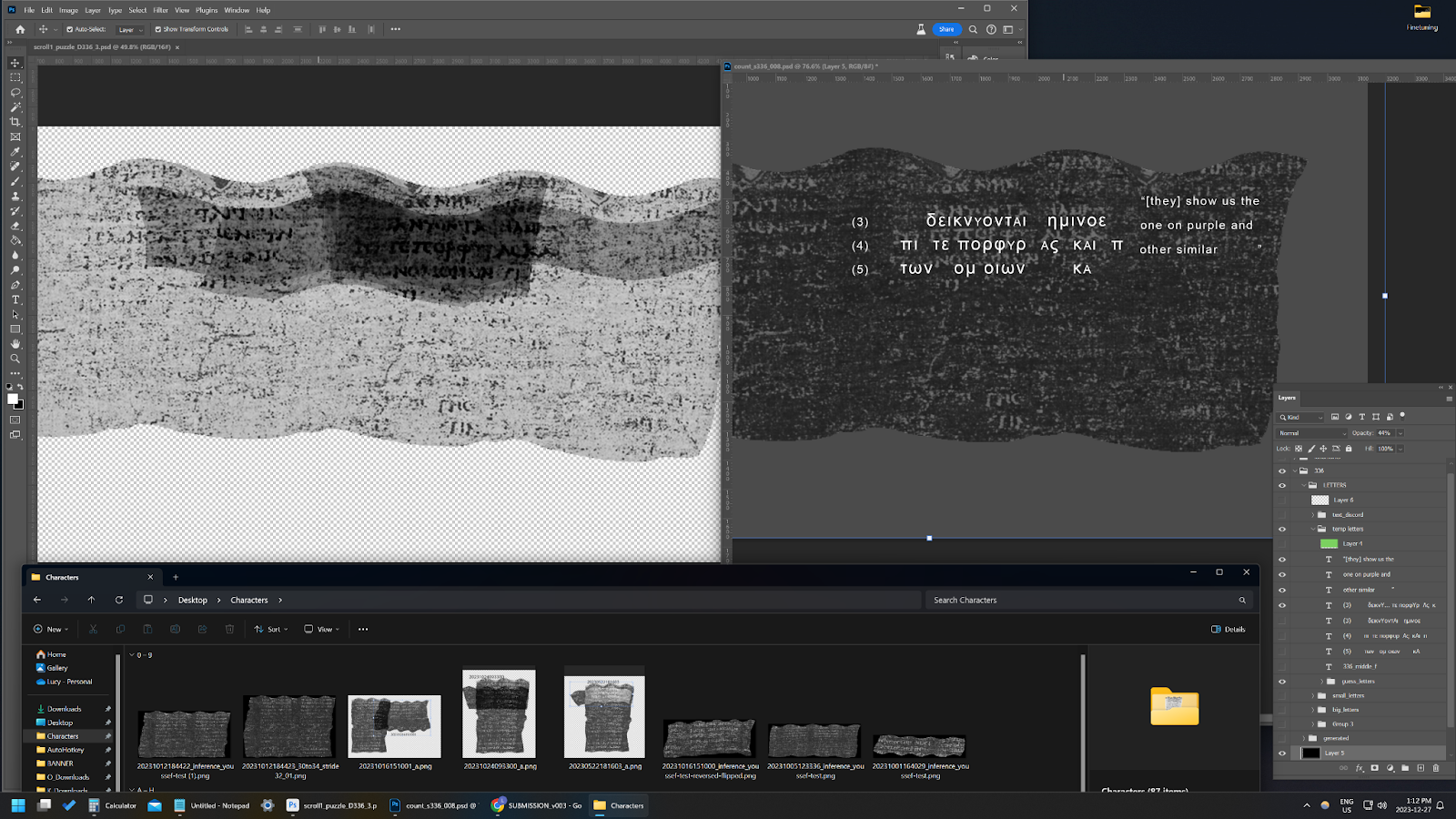
Passage 1: Segment 20231005123336


μα αβϛμ
κμλνκαμκχ
δεικνυονται ημιν ο ε
πι τε πορφυρας και
των ομοιων
πξ πως ανκω
μπουφαν
κυνζο
ϛχρξγυμ οχκ
ψπϛξζωνπν
λαων γηϛκω
μξββνινοθγϛω
————————-
But a rite or but a custom
are shown to us those who…
[they] show us the
one on purple and
other similar
how do I recover (how am i doing)
Hunter
unknown
Of the people of the land
————————
are indicated by e
pi te purple and
of the same
how am i doing
jacket
hound
ϛhrxgym ohk
ψπϛξzonpn
people’s land
μξβνινοθγϛω
————————-
μα αβϛμ (ma absm): Could be “μα αβεσμός” (ma abesmos), meaning “but a rite” or “but a custom”.
κμλνκαμκχ (cmlnkamkh): Perhaps “κοινολνκαμκχ” (koinolnkamkh), though the meaning is unclear.
δεικνυονται ημιν ο ε (are indicated by e): Likely “δείκνυνται ημίν οι ε” (deiknyntai hemin hoi e), meaning “are shown to us those who…”.
πι τε πορφυρας και (pi te purple and): Appears correct, “πι τε πορφύρας και” (pi te porphyras kai), meaning “both purple and”.
των ομοιων (of the same): Appears correct, meaning “of the similar ones”.
πξ πως ανκω (how am i doing): Could be “πως ανακω” (pos anakō), meaning “how do I recover”.
μπουφαν (jacket): “μπουφάν” is modern Greek for “jacket”. It’s anachronistic for ancient Greek.
κυνζο (hound): Could be “κυνηγό” (kynēgo), meaning “hunter”.
ϛχρξγυμ οχκ (ϛhrxgym ohk):
ψπϛξζωνπν (ψπϛξzonpn):
λαων γηϛκω (people’s land): Could be “λαών γης κω” (laōn gēs kō), meaning “of the people of the land”.
μξββνινοθγϛω (μξβνινοθγϛω):
Passage 2: Segment 20230702185753


λ..νπ.τωφ
.λτρϛρτπτλκτ
πλυνίαροαγ
.τ..πωνπρ
ν.ν.κρ.ο.τ
..υνγριπο
να….τϛ
κ..λρταιν
γ….μαρπλ
ϛ..ρλ.ο.υτ.ι
.πτυ.ποω.ακ
….λ..νρ
.π.ο.τίπ
..ρ….λυοψ
..ω.λαμυψρ
Old– γπλ μαλχπο
New- γπλ μαλχου
ντιπλιοαλ
.π..πγ.κνκ
————————
λ . . νπ . τωφ: “τωφ” could be a form of “τω φ”, meaning “to the”.
λτρ ϛρ τπτλϰτ: Hard to interpret. Could be a series of abbreviations or specialized terms.
π λ υϰία ρο αγ: “υϰία” (hykia) could mean “health” or “well-being”. “ρο αγ” is unclear.
τ π ϰ π ρ: Could be parts of words or abbreviations.
ν ν .ϰ ρ. ο . τ: ν ν” could be repetitions or part of a larger word.
υν γριπο: “υν” might be part of a word. “γριπο” (gripo) is not a recognizable Greek word but might be a name or specific term.
ν α . . . τϛ: “ν α” could be the start of a word.
κ λ ρ τ α ι ν: Could be initials or abbreviations. Hard to form a coherent word.
γ . . . μ ραπλ: “ραπλ” is not a standard Greek word but could be a part of a larger term or a specific name.
ϛ ρλ .ο. υ τ ι: “ρλ” is unclear. Could be part of a name or term.
πτυ ποω αϰ: “πτυ” could be a form of “πτύω”, meaning “to spit”.
λ . . ν ρ:
π ο τ ί π:
ρ . . λ υ οψ:
ω λ αμυ ψρ: “αμυ” could be part of “αμυνω” (amyno), meaning “defend”. The rest is unclear.
γ π λ μαλχ π ο: “μαλχ” could be a form of “μαλαχ”, a variant of “μαλακός” meaning “soft” or “gentle”.
ντι πλ ιο α λ:
π γ κνκ:
Passage 3: Segment 20231012184423 (left)




(1) Λ
Letters from the LEFT column:
Λ
Ρ..ΕΙΑΒΡ.Μ.Ρ
ΗΥΠΕΡ.Η..ΖΝ.
.ΕΠΑΡΑΤ.ΑΡ.Π.
..Ν.ΤΡΝ.ΗωΊΝΑΤΑ
ΤΡ.Τ.ΥΓ..Τ. ΥΨ
ϟΝ ιι.Τ.ΡΝ..ΤΡΠ
ΡΚΤΟΑΡ….Τ.ΑΜ
.Γ…Α.ΟΝΑΤΑ..Γ
ΤΕ…….Υ..Π….ϟ
ΙΤΟΥΙΓΤ ωΙ……..
..Χ…………
..Π.ιι.Γ….ΙΗΝ
ΓΥΜΗΕΕΙω..ΙΑ.Ρ……
.ΝΙΑωΙ……..Γ
ΔΙΗΙΜΑΡΙ.ιιΤ..
ΤΟω………….
ΤΟΥΡωΑ..ΑΥΓϟ
————————-
Spellchecked
Λ
Ρ..ΕΙΑΒΡ.Μ.Ρ
ΗΥΠΕΡ.Η..ΖΝ.
.ΕΠΑΡΑΤ.ΑΡ.Π.
..Ν.ΤΡΝ.Ή ΊΝΤΑ
ΤΡ.Τ.ΥΓ..Τ. ΥΨ
ϟΝ ιι.Τ.ΡΝ..ΤΡΠ
ΕΚΤΟΡ….Τ.ΑΜ
.Γ…Α.ΟΝΑΤΑ..Γ
ΤΕ…….Υ..Π….ϟ
ΡΙΤΟΥΙΤ ωΙ……..
..Χ…………
..Π.ιι.Γ….ΙΗΝ
ΓΥΜΗΕΕΙω..ΙΑ.Ρ……
.ΝΙΑωΙ……..Γ
ΔΙΗΙΜΑΡΙ.ιιΤ..
ΤΟω………….
ΤΟΥΡνΑ..ΑΥΓϟ
Passage 4: Segment 20231012184423 (right)
Letters from the RIGHT column:
Τ
ΤΜϚΥΡΡΚϚΜ
ΑΓΡCΤΛΜΑ
ΠΡΩΛCΠΔΝΜΛΝΞΛ
ΝΠΕΡΥΚΩΔΤ
ΡΩΜΖΟΓΥΤΥΖ
ΕΝΡΜΊΓΖΡΙΚΥΤϚΚΤ
ΚΝΑΓΛΑΝΜΡΙΤ
ΓΑΩΦΡΖΠΛ
ΠΤΛΥ
ΓΡΑΓΔΡΗϚΡ
ΧΚΜΛΙΡΡΤΗ
ΝTΤΝΤΠΡΚ
ΔΠCΑΤCΠΤΛ
ΡΖΩ
ΖΜΤΩΜΝΟΝΤΜ
ΡΣΣΜΤC
————————-
Λ [1/1]:
ΤμϚΥΡΡκϚμ [9/9]:
ΑΓΡCΤλμΑ [7/7]:
“ΑΓΡ” could be part of “ἀγρός” (agros, meaning field), but the presence of “C” is untypical in Greek.
ΠΡωλCΠδΝΜλΝξλ [11/11]:
“ΠΡ” might suggest “πρός” (pros, meaning towards).ΝΠεΡΥϰωδΤ [9/9]:
ΡωμζΟΓΥΤΥΖ [10/10]:
εΝΡμΊΓζΡΙΚΥΤϚϰΤ [12/12]:
ΚΝΑΓλΑΝμΡΙτ [12/12]:
ΓΑωΦΡΖΠλ [8/8]:
ΠΤλΥ [4/4]:
ΓΡΑΓΔΡΗϚΡ [7/7]:
ΧϰμλΙΡΡΤΗ [7/7]:
ΝtΤΝΤΠρκ [5/5]:
ΔΠCΑΤCΠτλ [6/6]:
Ρζω [3/3]:
ζμτωμΝΟΝΤμ [8/8]:
ΡςςμΤC [6/6]:
————————-
[1/1]
(2) ΤμϚΥΡΡκϚμ [9/9]
(3) ΑΓΡϚΤλμΑ [7/7]
(4) ΠΡωλϚΠδΝΜλΝξλ [11/11]
(5) ΝΠεΡΥϰωδΤ [9/9]
(6) ΡωμζΟΓΥΤΥΖ [10/10]
(7) εΝΡμΊΓζΡΙΚΥΤϚϰΤ [12/12]
(8) ΚΝΑΓλΑΝμΡΙτ [12/12]
(9) ΓΑωΦΡΖΠλ [8/8]
(10) ΠΤλΥ [4/4]
(11) ΓΡΑΓΔΡΗϚΡ [7/7]
(12) ΧϰμλΙΡΡΤΗ [7/7]
(13) ΝtΤΝΤΠρκ [5/5]
(14) ΔΠϚΑΤϚΠτλ [6/6]
(15) Ρζω [3/3]
(16) ζμτωμΝΟΝΤμ [8/8]
(17) ΡςςμΤϚ [6/6]
(18) Ϛ [1/1]
156/180
156/140
λ – Could be an abbreviation or initial for a word like “λόγος” (logos, meaning “word” or “reason”).
τμϛυρρκϛμ – Perhaps a distorted form of “τεμάχισμα” (temachisma, meaning “fragment” or “piece”).
αγρcτλμα – Might be a version of “αγρότημα” (agrotima, meaning “farm” or “estate”), with ‘c’ being a corruption.
πρωλcπδνμλνξλ – Could hint at “προδιαλέξω” (prodialexo, meaning “to preselect” or “choose in advance”), with some letters being extraneous.
νπερυκωδτ – Might be a jumbled version of “υπέρκοσμος” (yperkosmos, meaning “supernatural” or “transcendental”).
ρωμζογυτυζ – Resembles a garbled form of “ζωγράφος” (zografos, meaning “painter” or “artist”), with extra letters.
ενρμίγζρικυτϛκτ – Could imply “μυστικιστής” (mystikistes, meaning “mystic” or “occultist”), with considerable distortion.
κναγλανμριτ – Resembles a corrupted form of “καλλιγραφία” (kalligrafia, meaning “calligraphy”).
γαωφρζπλ – Might suggest “φωγράπης” (fographes, a distorted form of “photographer”).
πτλυ – Could be a shortened or corrupted form of “πτυχίο” (ptychio, meaning “degree” or “diploma”).
γραγδρηϛρ – Resembles a distorted version of “γραφείο διαχείρισης” (grafeio diacheirisis, meaning “management office”).
χκμλιρρτη – Might hint at “χειρουργός” (cheirourgos, meaning “surgeon”), with some letters being extraneous.
νtτντπρκ – Could imply “ντροπή” (ntropi, meaning “shame” or “embarrassment”), with extra letters.
δπcατcπτλ – Resembles a corrupted form of “διπλωματικός” (diplomatikos, meaning “diplomatic”).
ρζω – Might suggest “ρίζα” (riza, meaning “root”).
ζμτωμνοντμ – Could be a jumbled version of “ζωντανός μύθος” (zontanos mythos, meaning “living myth”).
ρσσμτc – Might hint at “μυστήριο” (mysterio, meaning “mystery”), with considerable distortion.
Lowercase, spell checked
λ/τ
τμϛυρρκϛμ
αγροκτημα
προλ c πδ νμ λνξ λ
νπερυκωδτ
ρωμζογυτυζ
ενρμίγζρικυτϛκτ
κναγλανμριτ
γαωρ ζπλ
πτλυ
γραγδρηϛρ
χκμλιρρτη
ντντ πρκ
δπcατcπτλ
ρζω
ζυμωνοντας
ρσσ μτc
————————-
l
τμϛυρρκϛμ
farm
prol c pd nm lnx l
close-up
romzogytyz
enrmižrikytϛkt
knaglamrit
gaor zpl
pl
register
hkmlirti
dnd prk
dpcatcptl
I’m sorry
fermenting
rss mtc
lowercase, No spaces
λ/τ
τμϛυρρκϛμ
αγρcτλμα
πρωλcπδνμλνξλ
νπερυκωδτ
ρωμζογυτυζ
ενρμίγζρικυτϛκτ
κναγλανμριτ
γαωφρζπλ
πτλυ
γραγδρηϛρ
χκμλιρρτη
νtτντπρκ
δπcατcπτλ
ρζω
ζμτωμνοντμ
ρσσμτc
————————-
l
τμϛυρρκϛμ
farm
prolcpdnmlnxl
close-up
romzogytyz
enrmižrikytϛkt
knaglamrit
geofrzpl
pl
register
hkmlirti
tttdprk
dpcatcptl
I’m sorry
zmtomnondm
rssmtc
Alternate reading based on guesses from community (discord)
Λ/Τ
ΤΜϚΥΡΡΚϚΜ
ΑΓΡCΤΛΜΑ
ΠΡΩΛCΠΔΝΜΛΝΞΛ
ΝΠΕΡΥΚΩΔΤ
ΡΩΜΖΟΓΥΤΥΖ
ΕΝΡΜΊΓΖΡΙΚΥΤϚΚΤ
ΚΝΑΓΛΑΝΜΡΙΤ
ΓΑΩΦΡΖΠΛ
ΠΤΛΥ
ΓΡΑΓΔΡΗϚΡ
ΧΚΜΛΙΡΡΤΗ
ΝTΤΝΤΠΡΚ
ΔΠCΑΤCΠΤΛ
ΡΖΩ
ΖΜΤΩΜΝΟΝΤΜ
ΡΣΣΜΤC
C
Uppercase, No spaces
Λ
ΤΜϚΥΡΡΚϚΜ
ΑΓΡCΤΛΜΑ
ΠΡΩΛCΠΔΝΜΛΝΞΛ
ΝΠΕΡΥΚΩΔΤ
ΡΩΜΖΟΓΥΤΥΖ
ΕΝΡΜΊΓΖΡΙΚΥΤϚΚΤ
ΚΝΑΓΛΑΝΜΡΙΤ
ΓΑΩΦΡΖΠΛ
ΠΤΛΥ
ΓΡΑΓΔΡΗϚΡ
ΧΚΜΛΙΡΡΤΗ
ΝTΤΝΤΠΡΚ
ΔΠCΑΤCΠΤΛ
ΡΖΩ
ΖΜΤΩΜΝΟΝΤΜ
ΡΣΣΜΤC
C
Λ [1/1]:
ΤμϚΥΡΡκϚμ [9/9]: “Ϛ” is an archaic letter (stigma), might be a “σ” (sigma) in some cases.
ΑΓΡCΤλμΑ [7/7]: “C” could be a “Γ” (gamma) or “Σ” (sigma).
ΠΡωλCΠδΝΜλΝξλ [11/11]: “C” could be “Σ”, “δΝ” might be a misreading, possibly “ΔΝ” (Delta-Nu) or “ΑΝ” (Alpha-Nu).
ΝΠεΡΥϰωδΤ [9/9]: “ϰ” is a kappa, “ωδ” might be a diphthong or two separate vowels “ο” and “δ”.
ΡωμζΟΓΥΤΥΖ [10/10]: “ζ” is not commonly found in the middle of Greek words; could be a “Σ”.
εΝΡμΊΓζΡΙΚΥΤϚϰΤ [12/12]: Several unusual combinations here, “ζ” could be “Σ”, “Ϛ” might be “Σ”, “ϰ” could be “Κ”.
ΚΝΑΓλΑΝμΡΙτ [12/12]: “τ” is not a Greek letter, it could be a misreading of “Τ” (Tau).
ΓΑωΦΡΖΠλ [8/8]: “ΦΡΖ” is an unusual sequence; “Ζ” might be a “Σ”.
ΠΤλΥ [4/4]: Appears legible, though “Υ” at the end of words is uncommon.
ΓΡΑΓΔΡΗϚΡ [7/7]: “ΔΡΗϚ” is an unusual sequence, “Ϛ” might be “Σ”.
ΧϰμλΙΡΡΤΗ [7/7]: “ϰ” is a kappa, “μλ” could be a misreading if it’s meant to be a single letter.
ΝtΤΝΤΠρκ [5/5]: “t” is not Greek; it could be a misreading of “Τ”.
ΔΠCΑΤCΠτλ [6/6]: “C” could be “Σ”, “τ” might be “Τ”.
Ρζω [3/3]: “ζ” is zeta; its placement is unusual in this sequence.
ζμτωμΝΟΝΤμ [8/8]: “ζ” could be “Σ”, “τω” could be a diphthong.
ΡςςμΤC [6/6]: “ς” is a final sigma; it should not appear in the middle of a word, “C” could be “Σ”.
C [1/1]: “C” is not Greek; could be a “Σ”.
————————-
Passage 5: Segment 20231106155351_inference_youssef-test

(1) . . . . Α. . .β . . .Γ ρ [4/11]
(2) . . . .λ . βΔ. . . . .ΓΟ [5/11]
(3) . ε . . . λ. . . . . .ς [3/9]
(4) ϰ . . . . . ορ . . . . [3/9]
(5) Μ . . . . . . . . . . [1/9]
(6) . . .ς . . . . . . . . [1/10]
(7) . . . . . . . . . [0/9]
(8) . ε. ψ. . .ψω . .ω [5/10]
(9) λ πωΙ ϰ ρ ϰ Γ . . . [8/11]
(10) . . . . . ω . . . [1/8]
(11) . . . . . . ω . . [1/8]
(12) . ϰ.ω Αζ χ . ω . . . [6/10]
(13) Ψω β Ν π Α π . [7/8]
(14) Φωυφζ Δ Τω. . [8/9]
(15) . .ϰ ςΑΜΨ . .ψ [6/10]
(16) .π ρ.ω ω .βΜ χ [7/10]
(17) π Φ β . . ρ . . [4/9]
(18) π . . . . π . . . [2/9]
180/140
180/216
————————-
Scroll 4 – 1667
Crackle

Characters
Lowercase letters from the Sostratos’s dataset
ι – ι (Iota)
ω – ω (Omega)
α – α (Alpha)
υ – υ (Upsilon)
lunate sigma (ϲ) (Sigma)
koppa (Ϙ) [not commonly used in modern Greek phonetics]
Α – α (Alpha)

Β – β (Beta)
Γ – γ (Gamma)
Δ – δ (Delta)
Ε – ε (Epsilon)
Ζ – ζ (Zeta)
Η – η (Eta)
Θ – θ (Theta)
Ι – ι (Iota)
Κ – κ (Kappa)
Λ – λ (Lambda)
Μ – μ (Mu)
Ν – ν (Nu)


Ξ – ξ (Xi)
Ο – ο (Omicron)
Π – π (Pi)
Ρ – ρ (Rho)
Σ – σ/ς (Sigma)
Τ – τ (Tau)
Υ – υ (Upsilon)
Φ – φ (Phi)
Χ – χ (Chi)
Ψ – ψ (Psi)
Ω – ω (Omega)
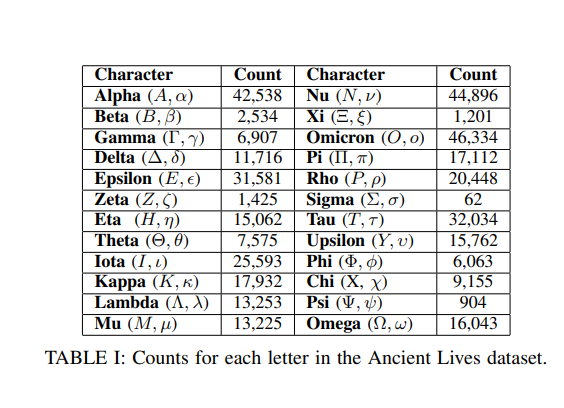
Frequency of characters of the txt file of Greek text:
93201 ; Α
88976 ; Ι
87344 ; Ε
82162 ; Ο
73875 ; Ν
67967 ; Τ
57473 ; Σ
40552 ; Υ
32029 ; Η
28600 ; Ρ
27995 ; Κ
27121 ; Ω
26666 ; Π
25352 ; Μ
23997 ; Λ
21515 ; Δ
14917 ; Γ
11154 ; Θ
7107 ; Χ
6460 ; Φ
3410 ; Β
2656 ; Ξ
1494 ; Ζ
994 ; Ψ
543 ;
31 ; ι
16 ; „
6 ; ω
3 ; α
3 ; υ
3 ; /
2 ; ⋯
2 ; \
1 ;
1 ; †
If the symbol resembles a backwards gamma (Γ), it could possibly be:
A Tau (Τ): Depending on the handwriting, the tau can sometimes look quite different from its standard form, especially in cursive or quicker scripts where the horizontal bar does not extend fully across.
An Iota with an accent: Iotas can be adorned with various accents in Greek; however, they are usually quite distinct in appearance from gammas and typically would not be mistaken for a tau.
A Stigma (Ϛ): This letter, which represents the combination of sigma (Σ) and tau (Τ), can sometimes appear similar to a backwards gamma, depending on the script.
A Koppa (Ϙ): An archaic Greek letter that was used in some regions and can sometimes appear similar to a backwards gamma.
Changing from miniscule to majuscule (lowercase to uppercase) seems to change the definition given by google translate slightly. It seems the lowercase is best for communicating the letter, but some characters are better represented by the uppercase. This is mostly noticeable for UPSILON (Y in uppercase, U in lowercase) and NU (N in uppercase, v in lowercase)
δεικνυονται ημιν ο ε
πι τε πορφυρας και
των ομοιων
are indicated by e
pi te purple and
of the same
ΔΕΙΚΝΥΟΝΤΑΙ ΗΜΙΝ Ο Ε
ΠΙ ΤΕ ΠΟΡΦΥΡΑΣ ΚΑΙ
ΤΩΝ ΟΜΟΙΩΝ
SHOWING E
PIT TE PORPHYRAS AND
OF S
Characters from paper (link)


Azure custom vision model labeling Drawn characters


Compositing
Segment 1: 20231005123336



Segment 2: 20230702185753






Segment 3: 20231012184423


Segment 4: 20231106155351 + 20231022170901 (20231022170900_superseded)


Replication Instructions:
# Vesuvius Scroll Challenge – Ink Detection
https://github.com/lucyellu/inkception-3d
This repository contains training and inference code based on an I3D architecture to detect ink from image stacks.
The easiest way is to clone the repo and open the jupyter notebooks in a colab environment. Then simply run the cells of interest.
“`
| git clone https://github.com/lucyellu/inkception-3d.git |
“`
Otherwise- to install and run locally:
### Set up a python environment. Tested with python 3.10
“`
| conda create –name python310 python=3.10 conda activate python310git clone https://github.com/lucyellu/inkception-3d.git cd inkception-3d pip install -r requirements.txt |
“`
note the following packages need to be installed
“`
pytorch-lightning
typed-argument-parser
segmentation_models_pytorch
albumentations
warmup_scheduler
“`
#if you run into cudaa or other compatibility issues, try installing with no version requirements
“`
| pip install -r requirements_noversions.txt |
“`
## Download Data
Download the segments that you want to inference or train with. ([paths](http://dl.ash2txt.org/full-scrolls/Scroll1.volpkg/paths/)).
Submission segments include:
20230702185753
20231012184423
20231005123336
20231106155351
20231022170901
Place the downloaded segment folders in the inkception-3d folder:
Place inference segments in /eval_segments
Place training segments in /training_segments
Make sure each {segmentid}_mask.png and {segmentid}_inklabel.png (if training) file is in its appropriate segment folder.
### Inference
Place the segment data you want to inference into ./eval_segments or adjust accordingly.
The inference_stride32 script runs a checkpoint model based on inception-3d. It saves progress images in a folder designated in outputs path at 2% intervals. Adjust as needed.
Arguments found within the InferenceArgumentParser class.
Download public model checkpoint [here](https://drive.google.com/file/d/1fAGZbVPHW6q1hNiI2E2NKzf6TyELzOC4/view?usp=sharing)
“`
python inference_stride32.py –segment_id 20230702185753 –model_path ‘/content/drive/MyDrive/inkception-3d/models/valid_20230827161847_0_fr_i3depoch=7.ckpt’
“`
###
Some example outputs found at [Segment Browser](https://vesuvius.virtual-void.net/)
### Training
Adjust the CFG class in 64x64_256stride_i3d.py
These are the parameters you can adjust per inference or training run.
I found the default backbone setting to be different for the inference (efficientnet0) and training files (set to resnet) so make sure you select the one you want.
“`
python 64x64_256stride_i3d.py
Letter Grid
This tool is meant to assist in letter or character detection.
User can input characters into each cell which then updates dynamically for each instance of that symbol.So if you decide that an epsilon should actually be a theta, you can update all instances of that symbol.
Click on ‘Copy’ to print the row or entire grid to output which you can then paste into the Greek word detector.
Currently the grid is pre-populated with the characters from the first ink/letters section of Scroll 1.
δεικνΥοντΑι ημινοε
πι τε πορφΥρ Ας κΑι π
των ομ οιων κΑ
“`
#Scroll diagram
Ortho views of each segment
##in progress

#Coordinates
UV and XYZ of segments
Set 753
Letters start at
UV
2339, 11917
XYZ
3285, 5203, 13433
Ends at
14824, 1868
4555, 2217, 354
Middle
8297, 6700
4203, 3701, 7251
Seg 423
Middle
11357, 7652
2956, 3521, 6854
Passage 1 starts at
14841, 831
3558, 4957, 12941
Passage 1 ends at
21891, 14441,
3131, 2511, 924
Seg 336
Middle
15377, 5420
2774, 3908, 8463
Passage starts at
15130, 1530
235, 4944, 11759
Ends at
23086, 9882
2383, 2350, 5118
Seg 901
Middle
17440, 3830
2860, 4252, 10184
Passage starts at
16595, 1046
3272, 5084, 12665
Pages
20 to 26 middle top clear lambda (upside down v)
30 to 46 ink
, 30, 44,
Seg 351
Middle
8166, 5170
3244, 2157, 4977
Passage starts at
5154, 462
4037, 3346, 9015
Data
Some sample images:




Discussion
I tried fine-tuning but found the public/open sourced model (youseff’s valid7.ckpt) to be quite effective at detecting crackle (which was the only signal I wanted to feed it).
My intuition is that drawing masks is dangerous and needs to be done with great care. I thought risk of human hallucination of letters and thus injection of false data outweighed the incremental gains.
I’m really grateful for the community and all the open source tools that have been built. Rapushko’s contribution of chartres and segment masks was really helpful. More so as a point of reference than actually training data as I didn’t feel confident enough in all the masks to keep grinding/adjusting training parameters.
I agreed with Stephen’s changes to mask 20230929220924,
https://discord.com/channels/1079907749569237093/1108134343295127592/1181702053479841873
which led me to believe that more masks could use a closer look. The time I spent staring at the layers and masks was outweighing any increase of accuracy for me- diminishing returns so decided to put finetuning on hold to pursue other ideas.

I actually found more success with simple data manipulation and adjusting the inference code directly using the public checkpoint.
I found it interesting that setting the reverse = 0 line within the inference script had such drastic effects. You might expect backwards or upside down letters, but the output would be completely different.
This led me to believe that the model is using wider context of nearby layers. The papyrus patterns are usually 10 to 15 layers, while the crackle would usually be heaviest in 3 to 6 layers.
It also holds depth value within the greyscale values. You can tell the scale of certain artifacts are adjusting with how close it is to the scanner.
I spent a fair amount of time trying to get accurate dimensions of the scroll in relation to the data. We’re told that scroll 1 was scanned at a 8um resolution. So each tif slice is presumably 8um. I assumed that the 65 tif stacks were different from the 14.5k volumes- because each segment may have different dimensions in surface area and thickness- yet all have 65 tifs exported. This implies that the thickness of each individual tif has an elastic thickness depending on the particular segment from volume cartographer.
Discussions within the discord seemed to hint that the reverse parameter was flipping or transforming the images individually
*insert discord link
As a sanity check, I wrote some janky code to manually reverse the tif layers myself.
*insert colab link
This produced the same result as the youseff-output-test-reversed as hosted by jrrudolph’s Segment Browser.
The model is using the start.idx and end.idx to construct a 3D array and the order that they are positioned really matters. When reversed, the depth map is backwards with each individual tif flipped.
Imagine an image where there are two dots. One is larger than the other. This implies that the larger one is closer to the observer. When these images are positioned in a reverse order, that scale information is essentially scrambled.
Architecture
I used the kaggle and open sourced model as a starting point, which mostly uses efficientnet-b0 as a backbone. It’s architecture is based on inception-3d; a CNN architecture that is especially effective at video processing and action/movement detection.
I’ve tried various training runs but results have been mixed so I focused on data manipulation. Each 65 tif stack seems to have multiple papyrus pages, and thus potential for multiple pages of ink.
You can see the horizontal fibers disappear as you scrub through the layers. Each page seems to be roughly 10-16 pages. The ink seems to mostly lie within 3-6 layers on top of that.
Altering the start and end idx seems to yield different letters. Reversing the order of images also has huge impact.
This implies that there is depth information within each tif.
Reverse order
Confirmed that the reverse is referring to the order of images and not some other form of manipulation or transform to the data. Also generated negative NO INK training data with the fragments (ground truth for ink/no ink available)
DRAFT
Scroll 1
Dimensions of unwrapped scroll likely to be
30 ft to 60 ft
due to
- radius of scroll (cylinder)
- thickness of papyrus
- max 360 segments in horizontal slices (14k tif) (based on page thickness and diameter)
- Historically, scrolls do not exceed 30 pages (900cm)
Methodology
Data Collection
Took backlight photographs of papyrus with ink/noink and befre/after carbonization in an airfryer
Processed frag1 segments with lightroom and python (reverse image sequence)
Created OBJ models of scroll through 3D slicer and maya
Downloaded data from servers and community resources
-segment browser
Cropping segments to only text areas (masked out margins)
Resetting segments to have center focus line by line
peripheral inference seems to suffer (noted by kaggle winner 5 found improvement with throwing away edges
Data Preprocessing
I inferenced various segments with different layer combinations including:
-01 to 64 (entire stack)
-32 to 34 (middle)
-20 to 50 (segment browser)
-26 to 36
-01 to 21
-49 to 65
Isolating papyrus pages from one another seems to help differentiate ink.
Early experiments include taking kaggle dataset (mostly Fragment 1) to match the histogram min/max levels of the segment tif stacks (64 tif). The 53kev segments created by Hari Seldon were curiously not picking up ink with public model. Likely due to training data limited to scroll 1. Differences in processing scan data/calibration.
Reduced polygon mesh of segment obj exports from volume cartographer
90% twice
400k to 4k polygon/triangle count
Modeled estimated dimension flat unrolled scroll
Applied deformers to roll it, then set keyframes to animate it
Then copied those keyframes in reverse order to the rolled scroll
Rolled scroll segments needed to be mesh edited to have break in overlapping pages
Model Training
google colab with t4 and a100
1050 ti local card
Did finetuning with youseff’s stride script modified to accept *new data
Then used various stride, size, batchsize to get various outputs.
Hallucination Mitigation
Some basics:
Testing model on unseen data
Breaking up grids to below letter/character resolution- no full letters
Rotation/cropping of images
Due to the inaccessibility of the scroll and inability to get ground truth- seems to me that hallucination is unavoidable. It’s just where in the pipeline you want to introduce it. As I was trying to decipher the outputs, I found myself hallucinating greek characters all around me- my marble tile, carpet patterns- I started seeing upsilons and alphas everywhere.
I tried to get a sense of what plausible text might look like and tried to establish some ground truth with the exposed fragments or existing manuscripts. Even given perfect ink detection (these are visible letters/characters on exposed papyrus) – it can be hard to pick out words/definitions, let alone whole sentences and passages from deformed and digitally unrolled, then black box machine learning visualized.
One can often assess the accuracy needed with the number of operations done. Considering that this scroll was first created over 2000 years ago, the number of input/output cycles this object has to go through in order to be recovered is quite astounding. A cylinder of carbon that’s arranged just so- contains intelligence from our ancestors. Information from a different time. Communication that’s somehow survived the thread of existence for millenia. A message from the past. This scroll has time traveled further than anything like it (so far).
Letters from people just like us, from a world so distant and mysterious, we can only imagine
- different xray scanning parameters
- different xray image processing parameters
- different file formats
- different resolutions
- different sequencing (clockwise, reverse stacks)
- different interpretations of characters/words
a lot of operations
A lot of opportunities for errors to accumulate
Decreasing the amount of operations seemed critical.
CITATIONS
-Papers
-stephen’s
-seales
-marzia
-thalia (ocr)
–
-Greek characters:
https://kyle-p-johnson.com/assets/most-common-greek-words.txt
-Scanner:
https://hackaday.io/project/163791-x-ray-ct-scanner
-Machine learning:
https://github.com/JamesDarby345/segment-anything-vesuvius
https://github.com/WongKinYiu/yolov7
-Models:
https://cloud.google.com/tpu/docs/inception-v3-advanced
https://github.com/tensorflow/tpu/tree/master/models/experimental/inception
-Characters:
http://www.riedlberger.de/titivillus_instructions.pdf
https://sourceforge.net/projects/gimagereader
https://github.com/manisandro/gImageReader
https://www.i2ocr.com/free-online-greek-ancient-ocr
https://docs.google.com/drawings/d/13bNuYv3XiQPZIBk7D-QcfMxLIJiWfAYdTF1foSJ9LbY/edit
-Simulating Infrared Imaging
-ithaca
@article{asssome2022restoring,
title={Restoring and attributing ancient texts with deep neural networks},
author={Assael*, Yannis and Sommerschield*, Thea and Shillingford, Brendan and Bordbar, Mahyar and Pavlopoulos, John and Chatzipanagiotou, Marita and Androutsopoulos, Ion and Prag, Jonathan and de Freitas, Nando},
journal={Nature},
year={2022}
}
-pythia
@inproceedings{assael2019restoring,
title={Restoring ancient text using deep learning: a case study on {Greek} epigraphy},
author={Assael, Yannis and Sommerschield, Thea and Prag, Jonathan},
booktitle={Empirical Methods in Natural Language Processing},
pages={6369–6376},
year={2019}
}
https://www.sciencedirect.com/science/article/abs/pii/S1350449516302456
https://github.com/blirs/BLIRS
-Inception 3D
-Unet
-Community
luke’s repo/write up
casey’s blog post
youseff’s model
sam masked volumes
segment browser outputs
discord:
-reversing (clockwise/anticlockwise)
-letter sizing
-papyrus margins, order, thickness



Leave a comment